Del taller ferroviario al algoritmo – Ingeniería de Dominio
Cómo mi experiencia en mantenimiento ferroviario definió las variables clave para un modelo predictivo.

El problema: La incertidumbre en el mantenimiento.
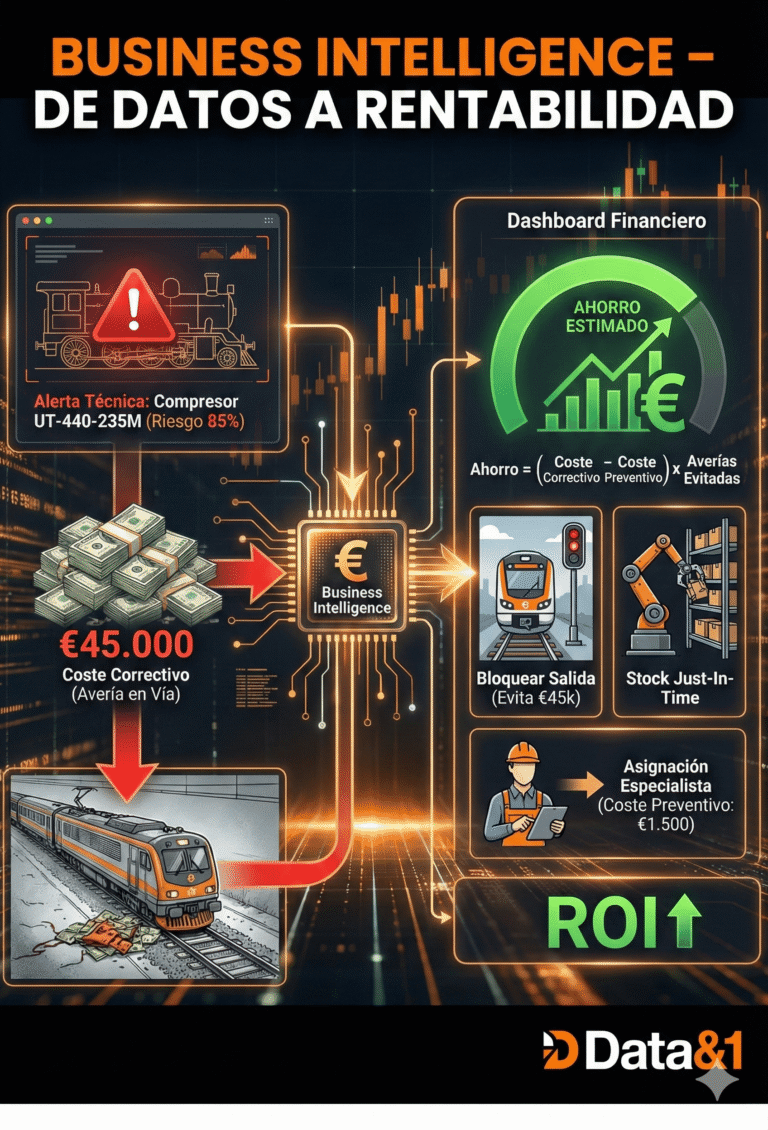
En el sector ferroviario en España, la disponibilidad de flota lo es todo. Un tren parado más tiempo del estipulado en taller por una avería imprevista («mantenimiento correctivo») es un coste exponencial: no solo es la reparación, es la cancelación del servicio, la insatisfacción del cliente, salir en prensa, y las penalizaciones operativas.
Durante mi experiencia profesional trabajando en una BMI (Base de Mantenimiento Integral) con series 440/470 (Media Distancia), 464/465 y 446 (Cercanías), identifiqué varios patrones de fallo radicalmente distintos que los sistemas tradicionales de gestión (GMAO) no estaban capturando eficazmente:
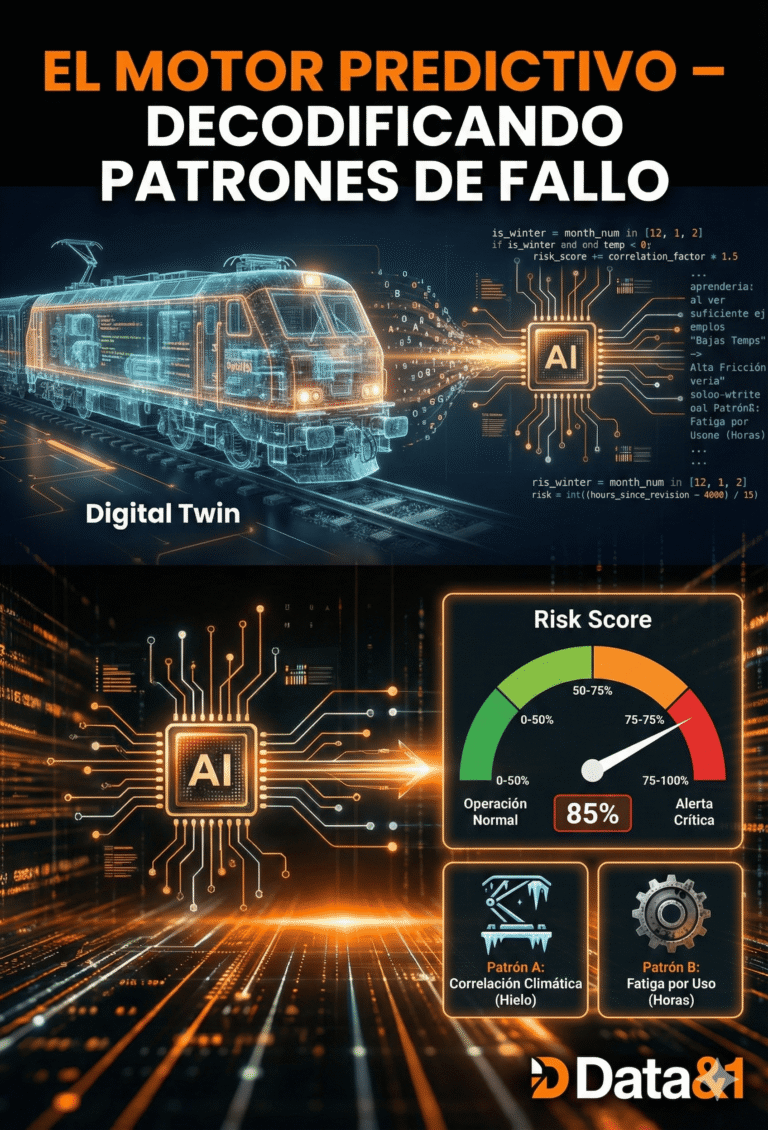
1. Series 440/470 (Flota Veterana, son UTs (Unidades Técnicas, como se le conoce en el sector, de más de 50 años operando): sus fallos están correlacionados directamente con el desgaste mecánico por horas de uso. En muchas ocasiones, las reparaciones se convierten en reconstrucciones, y casi en restauraciones. Algunos de los equipos, inevitablemente, acumulan lustros de desgastes que no se han podido, o no se ha sabido, escalorar en el tiempo. Un compresor falla no por temperatura ni aleatoriedad, sino por fatiga de material tras superar las 4,800 horas de ciclo, por ejemplo.
2. Series 464/465(Civia es su nombre comercial, son flota moderna, de entre 10 y 20 años de antigüedad): Sus fallos son más complejos, aunque parezca contradictorio, porque están vinculados a sensores y condiciones ambientales. Aquí interviene en un grado mucho mayor, la electrónica y su degradación programada. Componentes como un pantógrafo no falla por uso, sino por la combinación de bajas temperaturas (hielo en catenaria) y alta demanda de tensión (es un ejemplo, no representa todas las posibles averías que podría dar este componente).
La solución: Data Science aplicada.
En lugar de tratar todas las averías igual, decidí investigar y diseñar una arquitectura de datos que respeta la «física» de cada tren.

Definición de variables.
Para construir este proyecto, primero tuve que traducir el conocimiento «de taller» a variables de «Data Science», algo que, a pie de mecánicos, es casi ciencia ficción. He tomado, para este estudio, dos insights, uno para cada Serie.
Si, tú que estás leyendo esto, eres un profesional del sector, he tomado como base dos componentes, a modo de ejemplo. Mi intención es demostrar y validar un cambio necesario en el sistema de transporte ferroviario español, aplicando todas las ventajas de la tecnología, potenciada con IA, bajo el control, obviamente, de los expertos del sector:
* Variable Objetivo ($y$): Probabilidad de Fallo Crítico (Risk Score 0-100).
* Features ($X$):
* `Temp_Ambiente`: Crítico para Civia, menos relevante para 440.
* `Horas_Ciclo`: La predicción principal para la 440.
* `Voltaje_Catenaria`: Telemetría (simulada) para detectar picos de consumo.
Metodología.
El primer paso no fue programar, sino estructurar el conocimiento. Creé una matriz de riesgo que clasifica las averías en «predecibles por uso» (deterministas) y «predecibles por patrón» (estocásticas).
> «La Inteligencia Artificial no reemplaza al experto ferroviario; digitaliza su intuición para que sea escalable.»
En el siguiente artículo, explicaré cómo transformé estos conceptos abstractos en una estructura de datos real (JSON) capaz de alimentar una aplicación web.